How the DeepSee Query Engine Works
This appendix explains how DeepSee executes queries. You may find this information useful when you are viewing query plans or diagnosing problems. This appendix discusses the following topics:
This appendix provides some information on globals used internally by DeepSee. This information is provided for demonstration purposes; direct use of these globals is not supported. The organization of these globals is subject to change without notice.
Introduction
This section introduces the basic concepts. The next section provides a more detailed description.
Use of Bitmap Indices
When you compile a cube class, DeepSee creates the fact table class that the engine uses. This class defines all bitmap indices as needed by the engine; these are stored in the global ^DeepSee.Index. When you build or synchronize a cube, DeepSee updates these indices as appropriate. When it is necessary to find records in the fact table, the query engine combines and uses these bitmap indices as appropriate.
As an example, one bitmap index provides access to all the records that contribute to the Snack member of the Product Category level. Another bitmap index provides access to all the records that contribute to the Madrid member of the City level. Yet another provides access to all the records that contribute to the 2012 member of the YearSold level. To find all the records that contribute to Snack, Madrid, and 2012, DeepSee combines those bitmap indices and then uses the resulting index to retrieve the records.
Caching
For any cube that uses more than 512,000 records (by default), DeepSee maintains and uses a result cache. In this case, whenever DeepSee executes queries, it updates the result cache, which it later uses wherever possible. The result cache includes the following globals:
-
^DeepSee.Cache.Results, which contains values for each query previously executed for a given cube. This global also contains meta-information about those queries that can be used to quickly rerun them. To retrieve information for a query, DeepSee uses the cube name and the query key, which is a hash of the normalized query text.
For a given cube name and query key, this global includes a set of subnodes that contain final and intermediate values. These subnodes are organized by bucket number and then by result cell. (A bucket is a contiguous set of records in the source table; see the next subsection.)
The following shows an example:
^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",-1,2,3)=67693.46 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",-1,2,4)=425998.02 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",-1,2,5)=212148.68 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",0,2,3)=301083.77 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",0,2,4)=1815190.08 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",0,2,5)=910314.95 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",1,2,3)=78219.74 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",1,2,4)=463165.12 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",1,2,5)=233031.39 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",2,2,3)=79153.44 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",2,2,4)=461472.97 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",2,2,5)=233584.42 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",3,2,3)=76017.13 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",3,2,4)=464553.97 ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",3,2,5)=231550.46In this example, the first subscript after "data" indicates the bucket number. Buckets –1 and 0 are special: the –1 bucket is the active bucket (representing the most recent records), and the 0 bucket is the consolidated result across all buckets.
The final subscripts indicate the result cell by position. The value of the node is the value of the given result cell.
For example, ^DeepSee.Cache.Results("HOLEFOODS","en2475861404","data",0,2,3) contains the consolidated value for cell (2,3) across all buckets. Notice that this number equals the sum of the intermediate values for this cell, as contained in the other nodes.
-
^DeepSee.Cache.Axis, which contains metadata about the axes of previously run queries. DeepSee uses this information whenever it needs to iterate through the axes of a given query. It does not contain cached data.
-
^DeepSee.Cache.Cells, which contains cached values of measures for cells returned by previously executed queries. A cell is an intersection of any number of non-measure members (such as the intersection of Madrid, Snack, and 2012). In this global, each cell is represented by a cell specification, which is a specialized compact internal-use expression. The following shows a partial example:
^DeepSee.Cache.Cells("HOLEFOODS",1,":::2012:::::1:1::1:1",1)=$lb(1460.05) ^DeepSee.Cache.Cells("HOLEFOODS",1,":::2012:::::1:1::1:2",1)=$lb(606.22) ^DeepSee.Cache.Cells("HOLEFOODS",1,":::2012:::::1:1::1:3",1)=$lb(40.17) ^DeepSee.Cache.Cells("HOLEFOODS",1,":::2012:::::1:1::1:4",1)=$lb(63.72) ^DeepSee.Cache.Cells("HOLEFOODS",1,":::2012:::::1:1::2:1",1)=$lb(3778) ^DeepSee.Cache.Cells("HOLEFOODS",1,":::2012:::::1:1::2:2",1)=$lb(1406.08) ^DeepSee.Cache.Cells("HOLEFOODS",1,":::2012:::::1:1::2:3",1)=$lb(117.31) ^DeepSee.Cache.Cells("HOLEFOODS",1,":::2012:::::1:1::2:4",1)=$lb(412.24)The first subscript is the cube name, the second is the bucket number, the third is the cell specification (":::2012:::::1:1::1:1" for example), and the last indicates the measure. The value of a given node is the aggregate value of the given measure for the given cube, cell, and bucket. In this case, the results are expressed in $LISTBUILD form for convenience in internal processing. Notice that this global does not use the query key; this is because the same cell could easily be produced by multiple, quite different queries.
This global is known as the cell cache and is populated only when the cache uses buckets.
The cell cache does not include values for the active bucket. Nor does it include values for the 0 bucket (consolidated across all buckets).
These globals are not populated until users execute queries. The cache grows in size as more queries are executed, resulting in faster performance because DeepSee can use the cache rather than re-executing queries.
Note that the cache does not include values for any properties defined with isReference="true". These values are always obtained at runtime.
Buckets
For any cube that uses more than 512,000 records (by default), DeepSee organizes the cache into buckets. Each bucket corresponds to a large number of contiguous records in the fact table, as shown in the following figure:
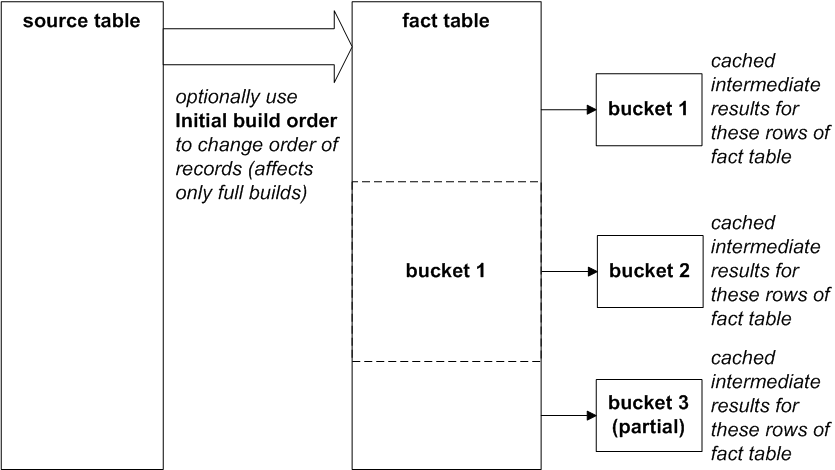
The final bucket (or partial bucket) is the active bucket and is not represented in the cell cache.
By default, the fact table contains records in the same order as the source table. You can specify Initial build order for the cube to control the order in which DeepSee examines the source table records when it performs a full build of the cube; see “Other Cube Options” in Defining DeepSee Models.
Whenever the fact table is updated, DeepSee discards parts of the cache as appropriate. More specifically, DeepSee invalidates any buckets that use records from the affected part or parts of the fact table. Other buckets are left alone. When it executes a query, DeepSee uses cached data only for the valid buckets. For records that do not have valid cached results, DeepSee uses the bitmap indices and recomputes the needed intermediate values. As the last phase of query execution, DeepSee consolidates the results. Thus DeepSee can provide results that come from a combination of cached data and new or changed data. Also, because some of the engine work can be split by bucket, DeepSee can (and does) perform some processing in parallel.
Default Bucket Size
By default, a bucket is 512,000 records. The bucket size is controlled by the bucketSize option, which expresses the bucket size as an integer number of groups of records, where a group is 64,000 contiguous records. The default bucketSize is 8, so that the default bucket is 8 x 64,000 records or 512,000 records. For information on bucketSize, see “<cube>” in Defining DeepSee Models.
Engine Steps
To process a query, DeepSee performs the following steps:
-
Preparation, which occurs in process (that is, this step is not launched as a background process). In this phase:
-
DeepSee parses the query and converts it to an object representation, the parse tree.
In the parse tree, each axis of the query is represented separately. One axis represents the overall filtering of the query.
-
DeepSee converts the parse tree to a normalized version of the query text.
In this normalized version, for example, all %FILTER clauses have been combined into a single, equivalent WHERE clause.
-
DeepSee generates a hash that is based on the normalized query text. DeepSee uses this hash value as the query key. The query key enables DeepSee to look up results for this query in the globals discussed in this appendix.
-
If DeepSee finds that it is possible to reuse previous results for this query (from ^DeepSee.Cache.Results), DeepSee does so and skips the following steps.
-
-
Execute axes, which also occurs in process. In this phase:
-
DeepSee executes any subqueries.
-
DeepSee examines the slicer axis (the WHERE clause), merges in any relevant filtering (such as from a subject area filter), and updates ^DeepSee.Cache.Axis with information about this axis.
-
DeepSee examines each of the remaining axes and updates ^DeepSee.Cache.Axis.
-
-
Execute cells, which occurs in the background (in multiple parallel processes). In this phase, DeepSee obtains intermediate values for each cell of the results, separately for each bucket, as follows:
-
First DeepSee checks to see if ^DeepSee.Cache.Cell contains a value for the cell for the given bucket.
If so, DeepSee uses that value.
-
Otherwise, DeepSee uses the applicable nodes of ^DeepSee.Index to obtain the bitmap indices that it needs. DeepSee combines these bitmap indices and then uses the result to find the applicable records in the source table.
If the cache uses buckets, DeepSee adds nodes to ^DeepSee.Cache.Cell for use by later queries.
-
-
Consolidation, which occurs in process. In this phase:
-
For each slicer axis, DeepSee examines each result cell for that axis.
For each result cell, DeepSee finds all the nodes in ^DeepSee.Cache.Cell that contain values for this cell.
It then combines those values.
-
For each result cell, DeepSee then combines the results across the slicer axes and obtains a single value.
For information, see the next section.
DeepSee evaluates the CURRENTMEMBER function during the consolidation phase. In contrast, it evaluates other functions earlier in the processing.
-
Axis Folding
In the consolidation phase, if there are multiple slicer axes, DeepSee combines results across these axes, for each result cell. This step is known as axis folding.
Axis folding means that if a given source record has a non-null result for each slicer axis, that record is counted multiple times.
To determine whether axis folding is required, DeepSee considers all the filters applied to the query, from all sources: the subject area, the pivot table, and the dashboard. The net combination of these filters determines whether axis folding is needed, as follows. The following table lists the main possibilities:
| Form of Filter | Axis Folding Performed? |
|---|---|
| Single member. Example: [PRODUCT].[P1].[PRODUCT CATEGORY].&[Candy] | No |
| Single measure. Example: [MEASURES].[Units Sold] | No |
| A tuple (combination of members or of members and a measure). Example: ([Outlet].[H1].[City].&[7],[PRODUCT].[P1].[PRODUCT CATEGORY].&[Candy]) | No |
| Cross joins that use members wrapped in %TIMERANGE functions CROSSJOIN(%TIMERANGE([BirthD].[H1].[Date].&[10000],[BirthD].[H1].[Date].&[50000]),%TIMERANGE([BirthD].[H1].[Date].&[40000],[BirthD].[H1].[Date].&[NOW])) | Yes |
| Other cross joins. Example: NONEMPTYCROSSJOIN([Outlet].[H1].[City].&[7],[PRODUCT].[P1].[PRODUCT CATEGORY].&[Candy]) | No |
| The %OR function, wrapped around a set expression that lists multiple members. Example: %OR({[Product].[P1].[Product Category].&[Candy],[Product].[P1].[Product Category].&[Snack]}) | No |
| A set expression that lists multiple members but does not use %OR. Example: {[Product].[P1].[Product Category].&[Candy],[Channel].[H1].[Channel Name].&[2]} | Yes |
To create these expressions (as filters) in the Analyzer, you generally drag and drop items to the Filters box. To create the set expressions in the last two rows, you must use the Advanced Filter editor. Note that DeepSee automatically uses the %OR function when possible; the Advanced Filter editor does not display it as an option.
Query Plans
If you execute a query in the Query Tool, you can see the query plan. Similarly, if you execute a query programmatically (as described earlier in this book), you can call the %ShowPlan() method of your result set. For example:
SAMPLES>do rs1.%ShowPlan()
-------------- Query Plan ---------------------
**SELECT {[MEASURES].[AVG TEST SCORE],[MEASURES].[%COUNT]} ON 0,[AGED].[AGE
BUCKET].MEMBERS ON 1,[GEND].[GENDER].MEMBERS ON 2 FROM [PATIENTS]****
DIMENSION QUERY (%GetMembers): SELECT %ID,DxAgeBucket MKEY, DxAgeBucket
FROM DeepSee_Model_PatientsCube.DxAgeBucket ORDER BY DxAgeBucket**
**DIMENSION QUERY (%GetMembers): SELECT %ID,DxGender MKEY, DxGender
FROM DeepSee_Model_PatientsCube.DxGender ORDER BY DxGender**
**EXECUTE: 1x1 task(s) **
**CONSOLIDATE**
-------------- End of Plan -----------------
Note that line breaks and spaces have been added here to format the documentation properly for its PDF version.
Query Statistics
If you execute a query programmatically (as described earlier in this book), you can call the %PrintStatistics() method of your result set. For example:
SAMPLES>do rs1.%PrintStatistics()
Query Statistics:
Results Cache: 0
Query Tasks: 1
Computations: 15
Cache Hits: 0
Cells: 10
Slices: 0
Expressions: 0
Prepare: 0.874 ms
Execute Axes: 145.762 ms
Columns: 0.385 ms
Rows: 144.768 ms
Members: 134.157 ms
Execute Cells: 6.600 ms
Consolidate: 1.625 ms
Total Time: 154.861 ms
ResultSet Statistics:
Cells: 0
Parse: 3.652 ms
Display: 0.000 ms
Total Time: 3.652 ms
The values shown here are as follows:
-
Query Statistics — This group of statistics gives information about the query, which returned a result set. It does not include information on what was done to use that result set.
-
Results Cache is 1 if the results cache was used or is 0 otherwise.
-
Query Tasks counts the number of tasks into which this query was divided.
-
Computations indicates how much time was spent performing intermediate computations such as aggregating a measure according to its aggregation option. It does not include evaluating MDX expressions.
-
Cache Hits counts the number of times an intermediate cache was used.
-
Cells counts all the cells of the result set as well as any intermediate cells that were computed.
-
Slices counts the number of cube slices in the query. This count indicates the number of items on the WHERE clause.
-
Expressions indicates how much time was spent evaluating MDX expressions.
When the cache is used, Computations, Cache Hits, Cells, and Expressions are all zero.
-
Prepare, Execute Axes, Execute Cells, and Consolidate indicate how long different parts of the query processing took place. These parts are listed in order.
-
Total Time is the sum of those parts.
When the cache is used, Execute Cells and Consolidate are both zero, because those parts of the processing are not performed.
-
-
ResultSet Statistics — This group of statistics gives information about what was done to use the result set after it was returned by the result set. The values are as follows:
-
Cells counts the number of cells in the result set.
-
Parse indicates how long it took to parse the result set.
-
Display indicates how long it took to display it.
-
Total Time is the sum of those times.
-