Using the Ensemble Record Mapper
This chapter explains how to use the Record Mapper tool to work more easily with files containing delimited and fixed-width records in Ensemble productions. This chapter contains the following sections:
The following two chapters described Complex Record Mapping, where an individual record consists of a group of heterogeneous subrecords, and batch processing, where multiple records are grouped to be processed in a batch:
Overview
The Ensemble Record Mapper tool provides a quick, efficient way to map data in text files to persistent Ensemble messages and back again. In particular, the Management Portal user interface allows you to visually create a representation of a text file and create a valid object representation of that data which maps to a single persistent Ensemble message object. The process of generating both the target object structure and an input/output parser is automated, leaving only a few options for the persistent structure of the object projection. Ensemble generates the objects in such a way as to be a single persistent tree to provide complete cascading delete operations.
The Management Portal also provides a CSV Wizard to help you convert CSV (Character Separated Value) files into a record map structure. This is particularly useful for files which contain column headers, as the wizard uses the header names to create the record map properties corresponding to the columns in the sample file.
The Record Mapper handles simple records which are either delimited or have fixed-width fields. A record map consists of a series of fields, which identify data in the record, and composites, which organize fields into a unit. In delimited records, the hierarchal level of composites specify the separator that is used between fields. Within delimited records, you can have simple fields that are repeating. You can not have repeating composites. You can optionally ignore any fields in the incoming text file so that they do not waste space in the stored records.
The Record Mapper is not capable of dealing with mixtures of delimited and fixed-width data, nor is it capable of dynamically adjusting its parser or object structure based on the content of the incoming record other than handling repeating simple fields. See Sample Record Mapper Production for details.
The Complex Record Mapper allows you to handle structured records containing different record types, including the ability to handle structures with repeating records and mixed delimited and fixed-field records.
An additional feature of the Record Mapper package allows you to batch heterogeneous records by implementing a class which inherits from EnsLib.RecordMap.BatchOpens in a new tab. This class handles parsing and writing out any headers and trailers associated with a specific batch. For simple headers and trailers, the Record Mapper user interface permits the creation of a batch of type EnsLib.RecordMap.SimpleBatchOpens in a new tab. You can extend either of these two batch implementations if you need to process more complex header and trailer data.
When a RecordMap batch operation is creating a batch from individual records, it stores the partially constructed batch in an intermediate file. You can specify the location of this file using the IntermediateFilePath property on the batch operation. On a mirrored system, you can store the intermediate file on a network drive that is accessible to both the main and failover system. Then if a failover occurs the failover system can continue to append records to the incomplete batch. Since the incomplete batch is stored in a file and not in a Caché database, it is not automatically copied to the mirror system.
Creating and Editing a Record Map
This section describes how to create and edit a record map. It contains the following sections:
Introduction
You can create a record map using the Record Mapper page of the Management Portal. If your file is a delimited file, you can also use the CSV Record Wizard to further automate the process. As you develop your record map, you can view how a sample file displays in the record map.
The Record Mapper page includes a visual representation of the record map structure, and a simple interface which allows you to enter and manipulate the more detailed settings available for the record map components. It also allows you to reposition sibling elements (elements at the same level). One of the more important features of the user interface is that if you have a sample input file, a sample parse of the file will be attempted when the current record map is saved. You can address small issues in your record map directly from the Management Portal.
You can also create a record map directly using XML and the model classes.
Getting Started
To start the Record Mapper, select Ensemble > Build > Record Mapper. From here, you have the following commands:
-
Open — Displays the finder dialog box for you to choose an existing record map to open for editing.
-
New — Initializes the page for you to enter a new record map structure.
-
Save — Saves your record map structure as a class in the namespace in which you are working. Once saved, the object appears in the list of record maps.
-
Generate — Generates the record map parser code and the related persistent message record class object.
To generate an object manually use the GenerateObject()Opens in a new tab class method in EnsLib.RecordMap.GeneratorOpens in a new tab. It permits a number of options regarding the persistent structure of the generated objects, as noted in the comments for the method.
-
Delete — Deletes the current record map. You can optionally delete the related persistent message record class and all stored instances of the classes.
-
CSV Wizard — Opens the CSV Record Wizard to help automate the process of creating a record map from a sample file that contains comma separated values (CSV).
The Save operation only writes the current record map to disk. In contrast, the Generate operation generates the parser code and the persistent object structure for the underlying objects.
When you select the name of the record map on the left side of the page, you see the record settings on the right, where you can edit the properties of the record map itself. Before you can save a record map, you must add at least one field to your record map. The following sections describe these processes:
Once you have created a new Record Map or opened an existing one, the Record Mapper displays a summary of the fields defined in the Record Map on the left panel and, on the right panel, allows you to set the properties of the Record Map or of the selected field. If you have specified a sample data file, it is displayed above the left panel. For example, the following shows the Record Mapper with the Record Map properties in the right panel:
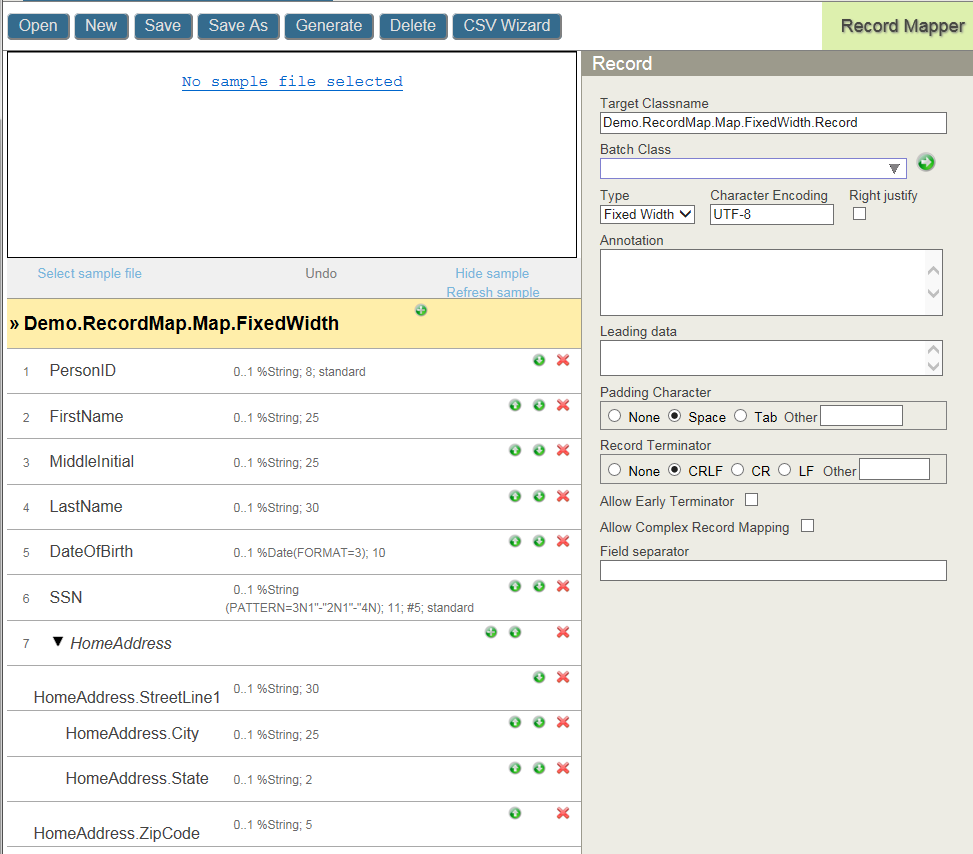
To export, import, or delete a Record Map, click Ensemble, List, and Record Maps to display the Record Map Lists page.
Common Control Characters
Within a record map, you can use literal control characters as well as printable characters in several places. For example, you can specify a tab character, which is a common control character as well as a comma, which is a printable character, as a separator. You can also specify control characters as a padding character or as one of the record terminator characters. To specify a control character in one of these contexts, you must specify the hexadecimal escape sequence for the character. If you select the space or tab character as the padding character, or CRLF (carriage return followed by a line feed), CR, or LF as the record terminator character in the Record Mapper, the Management Portal automatically generates the hexadecimal representation. If you are specifying another control character as the padding character or in the record terminator or any control character as a separator, you must enter the hexadecimal representation in the corresponding form field. The following table lists the hexadecimal escape sequence for commonly used control characters:
| Character | Hexadecimal representation |
|---|---|
| Tab | \x09 |
| Line feed | \x0A |
| Carriage return | \x0D |
| Space | \x20 |
For additional characters, see https://en.wikipedia.org/wiki/C0_and_C1_control_codesOpens in a new tab or other resources.
If you specify a record terminator in the RecordMap, the incoming message must match the record terminator exactly. For example, if you specify CRLF (\x0D\x0A), then the incoming message record must match that sequence.
Editing the Record Map Properties
Whether you are entering properties for a new record map, starting from the wizard-generated map, or editing an existing map, the process is the same. For the record itself, enter or update values in the following fields:
Name of the record map. You should qualify the record map name with the package name. If you do not provide a package name and specify an unqualified record map name, the record map class is saved in the User package by default.
Name of the Ensemble class to represent the record. By default, the Record Mapper sets the target class name to a qualified name equal to the record map name followed by “.Record”, but you can change the target class name. You should qualify the target class name with the package name. If you do not provide a package name and specify an unqualified target class name, the target class is saved in the User package by default.
Name of the batch class (if any) which should be associated with this record map.
The type of record; options include the following:
-
Delimited
-
Fixed Width
Character encoding for imported data records.
Flag that specifies that padding characters should appear left of data in fields.
Text that documents the purpose and use of the record map.
Static characters which appear before any data of the actual record contents. If you are using the record map in a complex record map, you must identify the record with leading data.
Character used to pad the value. The padding character is removed by business services from the incoming message and used by business operations to pad the field value to fill fields in fixed-width record maps.
-
None
-
Space
-
Tab
-
Other
Character or characters used to terminate the record.
-
None
-
CRLF
-
CR
-
LF
-
Other
Flag that specifies whether records can be terminated before the end. If allowed, record is treated as if it was padded with the padding character.
Flag that specifies whether record map can be used in a complex record map.
Optional single character used to separate fixed-width fields in records. If specified, input messages must contain this character between fields and business operations write this character between fields.
A list of field separator characters. The first separator delimits the top-level fields in the record. The next separator delimits fields within a top-level composite field. Additional separators delimit fields within nested composite fields.
A single separator character that is used in all repeating fields.
Radio button that specifies there is no quote-style escaping.
Radio button that enables quote-style escaping to allow a separator character to occur in a field value. Any input field can be quoted with the quote character. The field is considered all the characters between the start quote and end quote. Any separator character that appear within the quotes is treated as a literal character, not a separator. On output, any field that contains a separator in its value is quoted with the quote character.
Radio button that enables quote-style escaping to allow a separator character to occur in a field value. This has the same effect as Quote Escaping except that on output all fields are quoted whether they contain a separator character or not.
Character used to quote field contents. This field is displayed if you select the Quote Escaping or Quote All radio button. If you are using a control character as a quote, you must enter it in hexadecimal; see “Common Control Characters,” earlier in this chapter.
Editing the Record Map Fields and Composites
The Record Mapper left panel displays a summary of the fields defined in the Record Map. If you select a field, the right panel accesses the field properties. For example:
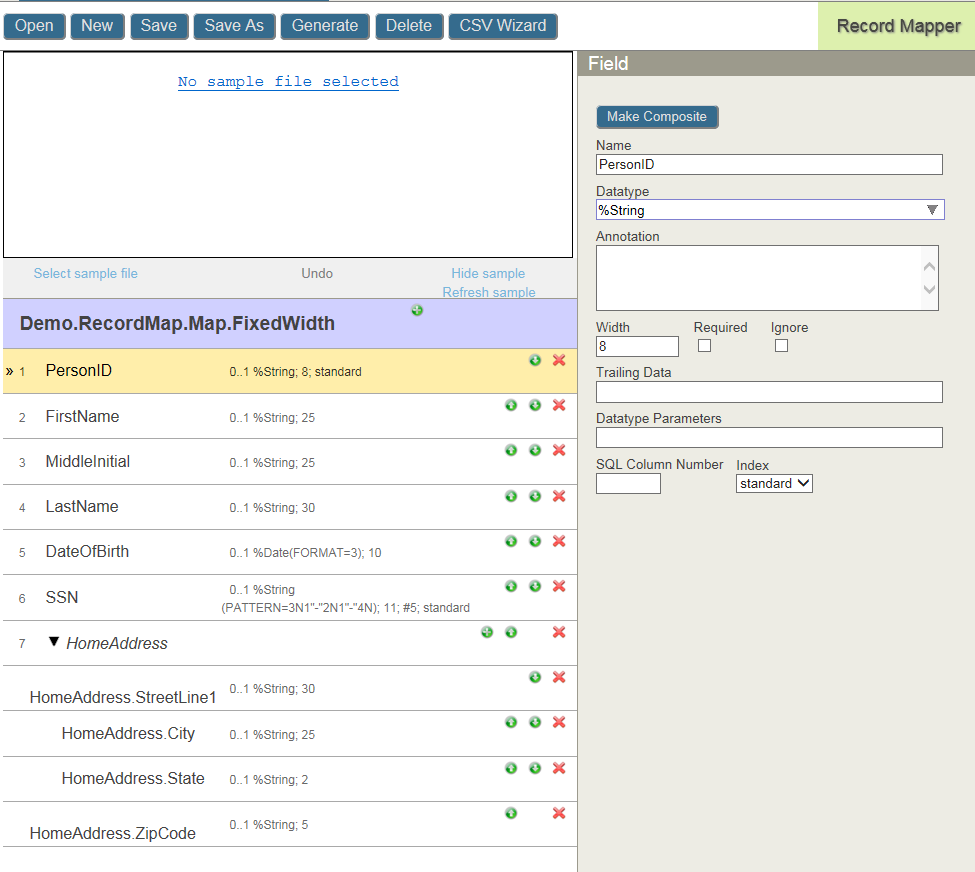
Record maps consist of a sequence of fields and composites. Each composite consists of a series of fields and composites. The Make Composite and Make Field buttons switch between a composite and a data field. For composite fields, you only specify the name and the flag indicating the field is required. Click the green plus-sign icon on the record map to add a field or composite to the top level. Clicking on the plus-sign of a composite allows you to add a field or composite to it.
While you are adding fields to your record map, you can open a sample file to see how its data maps to the record you are creating.
For delimited record maps, fields within composite fields have different separators. For example, in a record, the top-level field are delimited by commas, but within a composite the fields are delimited by semicolons. For fixed-width record maps, composite fields help organize the data conceptually, but do not impact the processing of the input message.
When you create a composite field in the Record Mapper, composite fields set the default name as a qualified name that matches the composite structure. The qualified field names determine the structure of fields within the generated record class. If you modify the field names to have different qualified names, the level of composite fields in the record map is independent from the structure of the fields in the generated record class.
For each data field you enter the following properties:
Name of the field.
Data type of the field. Select from the following list or enter a custom datatype:
-
%Boolean
-
%Date
-
%Decimal
-
%Double
-
%Integer
-
%Numeric
-
%String
-
%Time
-
%Timestamp
Documents the purpose and use of the field in the record map.
Width of the field.
Flag that specifies that the field is required.
Flag that specifies that the field may contain repeated values using the record map’s repeat separator character.
Flag that specifies the field is ignored on input and not included in the stored record. Using the Ignore property saves storage space for the stored records. On output, Ensemble outputs an empty value for ignored fields—for fixed-width records, it fills the field with spaces, and for delimited records, it writes two consecutive separators for the empty field.
Characters that must follow this field. Control characters must be entered in hexadecimal; see “Common Control Characters,” earlier in this chapter.
Parameters to apply to the data type separated by a semicolon.
The SQL column number of the field. This value must either omitted or be between 2 and 4096 (inclusive) as per the values for the SqlColumnNumber property keyword. The column number is of particular use when importing data from CSV files or similar data dumps, as the SQL representation can be replicated easily.
Enumerated value that controls whether the property should be indexed; select one of the following:
-
(blank) — do not index
-
1
-
bitmap
-
idkey
-
unique
The left panel of the Record Mapper is a table with a summary of the field definitions. The columns specify:
-
Top-level field number.
-
Field name.
-
Summary of the properties of the field. The summary contains the following information, separated by ; (semicolon):
-
ignored — present if the Ignore check box is selected.
-
0..1 or 1..1 followed by the datatype and datatype parameter — for optional or required fields, respectively.
-
Field width for fixed-width Record Maps.
-
#nnn — for SQL Column Number, if specified.
-
standard, bitmap, idkey, or unique — type of index, if specified.
For example, an SSN field in a fixed-width Record Map could have a summary 0..1 %String(PATTERN=3N1"-"2N1"-"4N); 11; #5; standard. This means it is an optional field, with a datatype and datatype parameters %String(PATTERN=3N1"-"2N1"-"4N), has a field width of 11, has an SQL column number of 5, and has a standard index.
-
-
Icons that allow you to move the field up or down or to delete the field. For composite fields, the plus icon allows you to add a new subfield.
Using the CSV Record Wizard
Ensemble provides a wizard to help automate the process of creating a record map from a sample file that contains comma separated values (CSV). You initiate the CSV Record Wizard either by choosing it on the Ensemble Build submenu or by clicking CSV Wizard from the ribbon bar on the Record Mapper page. The wizard handles only files with a single level of separator and does not handle leading data.
From the wizard, you enter values for the following fields:
Either enter the complete path with filename of your sample or click Select file to navigate and choose your sample file.
Enter the name of the record map to generate from your sample file.
Separator character used in the sample file. You must enter control characters in hexadecimal; see “Common Control Characters,” earlier in this chapter.
Specify how the sample file terminates a record. Choose one of the following:
-
CRLF — each record ends with a carriage return, followed by a line feed.
-
CR — each record ends with only a carriage return.
-
LF — each record ends with only a line feed.
-
Other — each record ends with control characters. Enter control character values in hexadecimal; see “Common Control Characters,” earlier in this chapter.
Select the type of character encoding used in the sample file.
Select this check box if the sample file you provide contains a header row.
In this case, Ensemble removes any punctuation and white space from values in the header row, and then uses the resulting values as property names in the record map. (If you do not select this option, Ensemble specifies the property names as Property1, Property2, and so on.)
Select this check box to keep the SQL column order in the generated object.
Select this check box and the quote character if the sample file uses quote-style escaping of the separator.
When you are finished filling out the wizard form, click Create RecordMap to generate a new record map from your sample file and return to the Record Mapper page. You can now refine your record map to add detail to the generated properties. See “Editing the Record Map Properties” for details.
Record Map Class Structure
There are two classes that describe a record map:
-
RecordMap that describes the external structure of the record and implements the record parser and record writer.
-
Generated record class that defines the structure of the object containing the data. This object allows you to reference the data in data transformations and in routing rule conditions.
A record map business service reads and parses the incoming data and creates a message, which is an instance of the generated record class. A business process can read, modify or generate an instance of the generated record class. Finally, a record map business operation uses the data in the instance to write the outgoing data using the RecordMap as a formatting template. Both the RecordMap class and the generated record class have hierarchical structures that describe the data, but the generated object structure does not have to be identical to the RecordMap structure.
When you create a new record map and then save it in the Management Portal, this action defines a class for that extends the RecordMap class. In order to define the generated record class, you must click Generate in the Management Portal, which calls the GenerateObject()Opens in a new tab method in the EnsLib.RecordMap.GeneratorOpens in a new tab class. If you are working in Studio, compiling the RecordMap class definition does not create the code for the generated record class. You must use the Management Portal or call the Generator.GenerateObject() method from the Terminal or from code.
The RecordMap consists of a sequence of fields and composites :
-
A field defines a data field with the specified type. The field type can specify parameters such as, VALUELIST, MAXVAL, MAXLEN, and FORMAT. In fixed-width records, the Record Mapper uses the field width to set the default value for the MAXVAL or MAXLEN parameters.
-
A composite consists of a sequence of fields and composites. Composites can be nested within a RecordMap.
By default, the Record Mapper in the Management Portal uses the composite level to set the qualified names of the fields. In delimited records, the nesting level of composites elements determines the separator used between fields as follows:
-
Fields in RecordMap that are not contained in a composite are delimited by the first separator.
-
Fields that occur in a composite that is in the RecordMap are delimited by the second separator.
-
Fields that occur in a composite that is itself within a composite are delimited by the third separator.
-
Each additional level of composite nesting increments the separator used to delimit the fields.
Composites in fixed-width records provide documentation about the structure of the data but do not impact how Ensemble treats the message.
Each RecordMap object has a corresponding record object structure. When you generate the RecordMap, the Record Mapper defines and compiles a record object that defines the object representation of the record map. By default, the Record Mapper in the Management Portal names the record “Record” qualified by the name of the RecordMap, but you can explicitly set of the name of the record object in the Target Classname field. By default, the Record Mapper names fields within composites by qualifying the name with the composites that contain it. If you use the default qualified names, the structure of the record object class properties will be consistent with the structure of the RecordMap fields and composites, but if you assign other names to the fields, the structure of the record object class properties will not match the structure of the RecordMap fields and composites.
The record object class extends the EnsLib.RecordMap.BaseOpens in a new tab, %PersistentOpens in a new tab, %XML.AdaptorOpens in a new tab, and Ens.RequestOpens in a new tab classes. If the RECORDMAPGENERATED parameter of the existing class is 0, then the target class is not modified by the record map framework — all changes are then the responsibility of the production developer. The properties in the generated record class are dependent on the names of the fields in the record map.
The properties of the record object class correspond to the fields of the record map and have the following names and types:
-
Names of fields with simple unqualified names that appear anywhere in the RecordMap or in composites within it. These properties have a type determined by the type of the field.
-
Top-level names of fields with qualified names that appear anywhere in the RecordMap or in composites within it. These properties have an object type with a class defined by the fields that share the same top-level qualified name. These classes extend the %SerialObjectOpens in a new tab and %XML.AdaptorOpens in a new tab classes. These classes are defined within the scope of the generated record class name. These classes, in turn, have properties corresponding to the next level of name qualification.
Consider an example, where you are defining a delimited record map, where the data contains three levels of separators, such as where the top-level separator field delimits the information about a person, the next level delimits the information about identification number, name, and phone number; and the final level delimits the elements within the address and name. For example, the message could start with:
French Literature,TA,199-88-7777;Jones|Robert|Alfred;
To define a RecordMap to handle these separators, you would need a composite at the level of person and one at the level of name. Thus the default field name for the FamilyName field could be Person.Name.FamilyName. This default name creates a deep level of class names in the record object class, such as the class NewRecordMap.Record.Person.Name that contains properties such as NewRecordMap.Record.Person.Name.FamilyName. You can avoid this deep level by prefacing the field names with the $ (dollar sign) character. If you do this, the classes and properties are all defined directly in the record scope. Using the same example, the class NewRecordMap.Record.Name would contain properties such as NewRecordMap.Record.FamilyName.
The names used to qualify the field names are used to define properties with an object type. Consequently, you cannot use a name both to qualify a field name and to be the last part of a field name, which would define a property with the same name with a data type.
Object Model for the RecordMap Structure
You can achieve the class structure behavior either by directly creating XML or by using the EnsLib.RecordMap.Model.* classes to create an object projection of the RecordMap. In general, the favored approach is to use Management Portal, but you may prefer to use the object model to create the RecordMap structure. The structure of these classes follows the RecordMap class structure; use the class reference for further information at this level.
Using a Record Map in a Production
When you choose to generate an object class on the Record Mapper page, you create a class that you can use in a business service of an Ensemble production.
Sample Record Mapper Production
The ENSDEMO provides a production named Demo.RecordMap.Production. This production demonstrates how to use Ensemble to process fixed files using the generated classes.